Zeer uitgebreide analyse en waardering van Nvidia, AMD en Intel aandelen
- Redactie

- 22 jun 2024
- 14 minuten om te lezen
In de wereld van AI semiconductors is er een duidelijke winnaar en hoge concurrentie. Nvidia is de onbetwiste leider met meer dan 90% marktaandeel in datacenter-GPU's en meer dan 80% marktaandeel in AI-processoren. Advanced Micro Devices (AMD) en Intel (INTC) zijn in het beste geval actieve concurrenten die AI-chips aanbieden als levensvatbare alternatieven voor Nvidia's H100 (de grafische verwerkingseenheid van het bedrijf). Maar Nvidia ligt ver voorop in het AI-spel en evolueert al naar de geavanceerdere H200 en het nieuwe Blackwell-platform later dit jaar. AMD en Intel hebben nog veel in te halen. De grotere bedreiging voor Nvidia is de aanval op het monopolie van CUDA, de eigen softwarestack van het bedrijf die ontwikkelaars in staat stelt de parallelle verwerkingsmogelijkheden van Nvidia-GPU's te benutten om machine learning-workloads te versnellen. Een concurrentie voordeel zo enorm, dat het bijna onmogelijk lijkt om CUDA te verslaan. Maar later meer..
Vanuit een aandelenprijs perspectief presteert Nvidia buitengewoon goed. De aandelen van Nvidia zijn het afgelopen jaar met bijna 200% gestegen, waardoor de AI-chipgigant het op twee na grootste bedrijf in de VS is geworden met een marktkapitalisatie van $2,97 biljoen, alleen Apple ($3,17 biljoen) en Microsoft ($3,21 biljoen) zijn groter. AMD-aandelen, hoewel niet in dezelfde klasse als Nvidia, hebben het goed gedaan met een stijging van bijna 45% in het afgelopen jaar, waardoor de marktkapitalisatie $260 miljard bereikte, 2x die van Intel.
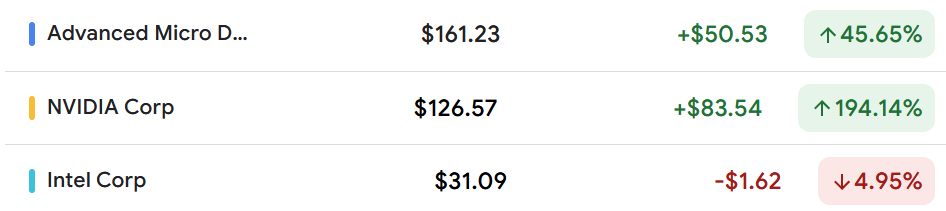
De achterblijver onder de drie is Intel, waarvan de aandelen dit jaar met 5% zijn gedaald en 40% onder de piek van december liggen, voornamelijk als gevolg van zwakkere vooruitzichten voor het tweede kwartaal. Dit artikel probeert inzicht te geven in de volgende vragen:
Is de verkoopgolf in Intel- en AMD-aandelen een koopkans?
Is Nvidia nog steeds een goede investering na de enorme rally?
Welke andere AI-aandelen zijn de moeite waard om te kopen naast Nvidia, AMD en Intel?
Waarom is de aandelenprijs van Intel op lange termijn gedaald in vergelijking met AMD en Nvidia?
Intel-aandelen zijn de afgelopen vijf jaar met meer dan 30% gedaald, tegenover een stijging van bijna 400% voor AMD en een verbazingwekkende stijging van meer dan 3000% voor Nvidia. Intel-aandelen kampen met uitdagingen als gevolg van de "technologiekloof die is ontstaan door meer dan een decennium van onderinvestering," aldus Intel-CEO Patrick Gelsinger. AMD is een belangrijke begunstigde geweest van de productieproblemen van Intel in het verleden.
De problemen van Intel begonnen met het missen van de boot op de 10nm en 7nm processen in chipproductie. Processors gemaakt met kleinere maar geavanceerdere nm (nanometer) processen zijn doorgaans sneller, presteren beter en zijn energiezuiniger.
Twee bedrijven die bloeiden door de productieproblemen van Intel zijn de Taiwan Semiconductor Manufacturing Company (TSMC) en AMD. Terwijl TSMC soepel door de 10nm en 7nm processen ging, groeide AMD, een fabless halfgeleiderbedrijf, zijn aandeel in de X86 server-CPU-markt van bijna nul naar 23,9% in het eerste kwartaal van 2024.
Intel miste ook de mobiele revolutie. De iPhone had een Intel-chip kunnen hebben, maar tegenwoordig wordt ongeveer 99% van de premium smartphones aangedreven door een op Arm gebaseerde chip. Dat was een kostbare fout, omdat Apple later stopte met het gebruik van Intel-chips in zijn computers, beginnend in 2020, en overging op zijn eigen op Arm gebaseerde chips, waarmee een 15-jarige samenwerking met Intel werd verbroken. Ter referentie: Apple Macs vertegenwoordigen ongeveer 10% van het wereldwijde PC-marktaandeel. Intel's verlies was de winst van Arm. ARM levert licenties aan bedrijven als Apple, Google en andere om zelf chips te kunnen ontwikkelen met hun gepatenteerde technologie.
Arm veroverde 9% van de totale CPU-servermarkt in 2023, terwijl Intel blijft domineren met een marktaandeel van 61%. Arm gebruikt de RISC-architectuur tegenover Intel's X86-instructieset die door de meeste pc's wordt gebruikt. Arm-gebaseerde chips verbruiken minder stroom in vergelijking met X86-gebaseerde chips en de laatste tijd hebben Arm-chips een significante toename in adoptie ervaren. Arm-architectuur vormt de kern van zowel de aangepaste server Graviton-chips van Amazon Web Services als de vlaggenschip Snapdragon-chips van Qualcomm.
Moeten Intel en AMD zich richten op concurrentie van Arm?
Het lijkt er wel op. Hier is waarom. Nvidia elimineert Intel volledig uit zijn nieuwste "Blackwell" GPU. Twee Nvidia B100 GPU's worden gekoppeld aan een op Arm gebaseerde processor. Dit is de reden dat Nvidia een overnamebod had gedaan op ARM. Als dit door was gegaan dan was Nvidia een mega monopolie. Maar overheden over de hele wereld hielden dit gezamenlijk tegen.
Ter referentie: AI-georiënteerde GPU-gebaseerde servers maken vaak gebruik van meerdere Nvidia GPU's, soms acht of meer, naast een Intel CPU om parallelle verwerking te vergemakkelijken, essentieel voor AI-taken zoals deep learning en neurale netwerktraining. Nvidia's nieuwste Grace Hopper Superchip combineert zijn eigen GPU's met de krachtige Neoverse-kernen van Arm.
Arm-gebaseerde chips voeden de Surface-laptops van Microsoft die op 18 juni worden verzonden. Deze laptops zijn uitgerust met de Snapdragon X Elite of Plus-chip van Qualcomm om effectiever te concurreren met de MacBook-laptops van Apple.
De eerste aangepaste Arm-gebaseerde CPU's van Google, de Axion-processors, ontworpen voor het datacenter, zullen later dit jaar beschikbaar zijn voor Google Cloud-klanten. Google zegt dat Axion-processors 30% betere prestaties zullen leveren dan de snelste algemene Arm-gebaseerde processors die beschikbaar zijn in de cloud en tot 50% betere prestaties en tot 60% betere energie-efficiëntie zullen bieden dan vergelijkbare huidige generatie x86-gebaseerde CPU's.
Het moet worden opgemerkt dat Intel een lagere marktkapitalisatie heeft in vergelijking met zelfs Arm. Maar dat ARM gigantisch duur is qua waardering. Met 41x P/S van volgend jaar en 109x P/E van volgend jaar.
Intel vs. AMD: Lancering van Intel Xeon 6 die AMD's EPYC-processors uitdaagt
Niet lang geleden begon Intel met de levering van de eerste van zijn volgende generatie Xeon-serverprocessors, een Xeon 6 "efficiency"-model (E-core) ontworpen voor publieke en private clouds waar energie-efficiëntie en prestaties cruciaal zijn. De krachtigere "performance" versie (P-core) van de Xeon 6, ontworpen om computationeel intensieve AI-modellen te draaien, zal in het derde kwartaal arriveren.
Veel hangt af van de Xeon 6-chips voor Intel in zijn pogingen om marktaandeel voor x86-chips in datacenters terug te winnen van AMD. Een Reuters artikel, stelt dat "Intel's marktaandeel in de datacentermarkt voor x86-chips met 5,6 procentpunten is gedaald in het afgelopen jaar tot 76,4%, terwijl AMD nu 23,6% in handen heeft."
Intel merkt op dat zijn Xeon 6 P-core-processors AI-inferenties 3,7 keer beter zullen uitvoeren dan AMD EPYC-processors, terwijl Xeon 6 E-core-processors 1,3 keer betere prestaties per watt zullen leveren dan AMD EPYC-chips bij mediatranscoding-workloads.
Het Xeon 6 'efficiency'-model heeft een 144-core count, wat het een voorsprong geeft op AMD's 4e generatie EPYC-processors met maximaal 128 cores. Een toenemend aantal cores betekent superieure prestaties omdat meerdere cores parallelle verwerking mogelijk maken.
AMD rust echter niet op zijn lauweren. AMD's vijfde generatie EPYC-processors, met de codenaam Turin, zullen tot 192 cores bevatten en arriveren in de tweede helft van dit jaar. Op zijn beurt plant Intel om begin volgend jaar een 288 e-core van de Xeon 6 uit te brengen. Dit soort announcements zijn ook strategisch zodat klanten wachten op de betere chip en niet meteen gaan inkopen bij de concurrent.
Intel en AMD richt enzich op Nvidia met lage prijzen voor Gaudi AI-chips
Intel prijs zijn Gaudi 2 en Gaudi 3 AI-chips veel goedkoper dan Nvidia's H100-chips. Intel beweert dat de nieuwe Gaudi 3-versneller "gemiddeld 50% betere inferentie en 40% betere energie-efficiëntie" levert dan Nvidia's H100 tegen "een fractie van de kosten." De Gaudi 3 zal breed beschikbaar zijn in het derde kwartaal.
Een Gaudi 3-versnellingspakket, dat acht AI-chips bevat, is geprijsd op $125.000, en de vorige generatie Gaudi 2 kost $65.000. De prijs van het Gaudi 3-versnellingspakket lijkt vergelijkbaar met de vlaggenschip AI-versnellers van AMD, de Instinct MI300-reeks, die ook direct concurreren met Nvidia's H100 GPU's. Naar verluidt verkoopt een Instinct MI300X GPU voor ongeveer $15.000.
De MI300X GPU van AMD, die al langer beschikbaar is, kon de vraag naar Nvidia's H100 AI GPU's, die naar verluidt tussen $30.000 en $40.000 kosten, ongeveer 2x hun prijzen, niet aantasten. Dus het is onzeker of de lage prijzen van Gaudi 3 een aanzienlijke impact zullen hebben op de vraag naar de H100, maar het moet worden opgemerkt dat Gaudi 3 ondersteuning heeft gekregen van grote spelers zoals Dell, HPE, Lenovo, Supermicro, Asus, Gigabyte en QCT. AMD verwacht volgend jaar de MI350-serie chips te lanceren. De MI350 is gebaseerd op een geheel nieuwe architectuur en zal naar verwachting 35x betere inferentiemogelijkheden hebben.
Nvidia blijft zijn eigen grootste concurrent
Waarschijnlijk in een poging om de kostenvoordelen van concurrenten te neutraliseren, heeft Nvidia solide rendementen op investeringen (ROI) van 5x tot 7x voor klanten die investeren in Nvidia-infrastructuur gesignaleerd. In feite is Nvidia zijn eigen grootste concurrent, omdat het overschakelt naar een nieuw "één-jaar ritme" om nieuwe chiparchitectuur vrij te geven, wat een significante versnelling betekent ten opzichte van de tweejarige cyclus.
Op de vraag hoe Nvidia-klanten, die miljarden dollars hebben uitgegeven aan bestaande producten, zouden reageren op de nieuwere aanbiedingen die snel de capaciteiten van bestaande producten overtreffen en de snelheid waarmee de waarde van de bestaande producten afneemt, suggereerde Huang dat prestatiegemiddelden de slimme manier zouden zijn voor bedrijven om om te gaan met "een heleboel chips die op hen afkomen" wanneer het maken en besparen van geld onmiddellijke prioriteiten zijn en tijd van essentieel belang is.
Nvidia heeft zorgen over een "vraagvertraging" weggenomen terwijl het overgaat van het huidige Hopper AI-platform naar het meer geavanceerde volgende generatie Blackwell-systeem. Blackwell heeft een inferentievermogen dat 30x dat van Hopper is, terwijl het 25x minder kosten en energie verbruikt. Dus analisten waren bezorgd of klanten hun Hopper-bestellingen zouden uitstellen vanwege de aankomende Blackwell-lancering. Nvidia zei echter dat het een toenemende vraag naar Hopper zag door het kwartaal (dat is nadat het Blackwell aankondigde) en verwacht dat de vraag de komende tijd groter zal zijn dan het aanbod tijdens de overgang. Bovendien zijn Blackwell-systemen ontworpen om achterwaarts compatibel te zijn, wat de overgang voor klanten gemakkelijk maakt. De vraag naar zowel Hopper als Blackwell-platforms ligt ver voor op het aanbod en zal naar verwachting doorgaan tot ver in het volgende jaar.
Intel verwacht dit jaar ongeveer $500 miljoen aan Gaudi 3-verkopen, terwijl AMD ongeveer $3,5 miljard aan jaarlijkse AI-chipverkopen ziet en Nvidia's datacenterbusiness met zijn AI GPU's naar schatting een verbazingwekkende $57 miljard aan verkopen zal genereren in de tweede helft van het jaar.
Nvidia's gigantische concurrentievoordeel en waarom het relevant blijft
Als de GPU's van Nvidia in overweldigende vraag blijven, is dat vanwege zijn CUDA-softwarestack die ontwikkelaars in staat stelt de parallelle verwerkingsmogelijkheden van Nvidia-GPU's te benutten om machine learning-workloads te versnellen.
Nvidia was jaren geleden klaar met de strijdharde CUDA voordat de boom in deep learning plaatsvond, waardoor het een vroege voorsprong kreeg. De uitgebreide bibliotheken en toolsets die zijn gebouwd op CUDA en de geïntegreerde native ondersteuning voor CUDA GPU-versnelling van belangrijke leermodellen zoals TensorFlow, PyTorch, Caffe, Theano en MXNet zetten de bal aan het rollen. CUDA werd de gouden standaard voor GPU-versnelling en raakte diep verankerd in alle aspecten van het AI-ecosysteem.
CUDA-alternatieven zoals AMD's MIOpen, Intel's oneAPI en zelfs vendor-onafhankelijke frameworks zoals OpenCL zijn gestruikeld door beperkte gebruikersadoptie als gevolg van onvoldoende tooling en ondersteuning vergeleken met CUDA. Het migreren van geavanceerde neurale netwerkcodebases van CUDA naar alternatieve programmeerparadigma's blijft een solide uitdaging.
Ondanks de mislukte pogingen om CUDA van de troon te stoten, heeft Nvidia nooit concurrentie onderschat. Integendeel, het zorgt ervoor dat het zijn marktdominantie behoudt door voortdurend de CUDA-capaciteiten en high-performance bibliotheken te evolueren om verschillende aspecten van deep learning-workflows op Nvidia GPU's te versnellen. Nvidia's samenwerkingen met onder andere de universiteit van Berkeley en Facebook helpen populaire deep learning-modellen op CUDA te optimaliseren. Bovendien is Nvidia de lieveling van een risicomijdende bedrijfscliëntenkring die de voorkeur geeft aan een bewezen technologie zoals CUDA.
Oorlogstrommels tegen Nvidia's CUDA die AMD bevoordelen
De inspanningen om de afhankelijkheid van Nvidia te verminderen en de toegang tot niet-CUDA-centrische versnelling te democratiseren, winnen aan momentum.
AMD richt zijn pijlen op de dominantie van Nvidia door gebruik te maken van zijn open-source ROCm-framework dat direct concurreert met de de facto CUDA-standaard. ROCm wordt ondersteund door Google's open-source machine learning framework TensorFlow, terwijl PyTorch, een ander belangrijk framework, aanvankelijke native AMD GPU-integratie heeft geïntroduceerd op experimentele basis om de CUDA-lock-in te verminderen.
Andere initiatieven van PyTorch omvatten Layer-wise Adaptive Rate Scaling (LARS) om deep learning-taken over diverse hardwareplatforms te schalen. Een verenigde geheugentoewijzer in PyTorch 1.11 brengt prestatieverbeteringen naar AMD GPU's en Apple M1-chips met verenigde geheugenarchitecturen, terwijl de grafiekmodusuitvoeringsback-end geïntroduceerd in PyTorch 1.5 ondersteuning uitbreidt naar workflows op niet-Nvidia-hardware zoals Intel geïntegreerde GPU's en budgetvriendelijke AMD-kaarten met doorgaans minder geheugencapaciteit.
OpenAI's zware investering in CUDA/ROCm-portabiliteitslagen zoals Triton is ook gericht op het verminderen van de afhankelijkheid van Nvidia.
Intel investeert zwaar om oneAPI als een betrouwbare alternatieve oplossing voor CUDA te positioneren. Hoewel CUDA niet van de ene op de andere dag zal verdwijnen, onderstreept het momentum in de verschuiving naar CUDA-alternatieven de realiteit dat het tijdperk van propriëtaire AI-hardwarestacks misschien niet voor altijd zal duren.
Nvidia staat op het punt de volgende golf van AI-groei te rijden
Soevereine AI: Nvidia verwacht dat de inkomsten uit Soevereine AI dit jaar de hoge enkele miljarden zullen benaderen, vergeleken met niets vorig jaar, door de AI-ambities van naties over de hele wereld een vliegende start te geven.
Automotive verticaal: Automotive wordt naar verwachting Nvidia's grootste zakelijke verticaal binnen het datacentersegment dit jaar, wat een miljardenomzetkans biedt over zowel on-prem als cloudgebruik.
Blackwell-platform: Het volgende generatie Blackwell-platform, dat realtime generatieve AI op biljoen-parameter grote taalmodellen mogelijk maakt, is in volledige productie met verzendingen gepland om te beginnen in het tweede kwartaal, en zal opschalen in het derde kwartaal met datacenters die klanten opzetten in het vierde kwartaal. Nvidia verwacht dit jaar veel Blackwell-inkomsten te zien.
Spectrum-X: In het eerste kwartaal begon Nvidia met de verzending van zijn nieuwe Spectrum-X Ethernet-netwerkoplossing die Ethernet-only datacenters in staat stelt grootschalige AI te accommoderen. Spectrum-X is in volume aan het opschalen met meerdere klanten en zou binnen een jaar moeten opschalen naar een miljardenproductlijn.
Intel's meester plan om een foundry te worden
Intel hoopt dat 2024 het dieptepunt zal zijn voor de operationele verliezen in zijn worstelende foundry business, die zijn operationele verlies verdiepte tot $7 miljard in 2023 van een verlies van $5,2 miljard in 2022 bij een omzetdaling van 31% op jaarbasis tot $18,9 miljard. Intel verwacht dat de foundry business halverwege tussen het huidige kwartaal en het einde van 2030 break-even zal draaien en aanzienlijke winstgroei zal stimuleren in de loop van de tijd.
In maart kreeg Intel tot $8,5 miljard aan directe financiering en de optie om federale leningen tot $11 miljard te ontvangen onder de CHIPS Act die gericht is op het bouwen van halfgeleiderfabrieken op Amerikaanse bodem, om te beschermen tegen een tekort aan aanbod als China ooit Taiwan zou binnenvallen. De voorgestelde financiering zal Intel helpen zijn commerciële halfgeleiderprojecten in Arizona, New Mexico, Ohio en Oregon te bevorderen, terwijl het zijn plannen ondersteunt om meer dan $100 miljard in de VS te investeren over vijf jaar om de Amerikaanse chipproductiecapaciteit en -mogelijkheden uit te breiden en AI-technologieën te versnellen.
Het was bijna zeker dat Intel een belangrijke begunstigde van de CHIPS Act zou zijn, omdat het fabrieken, of fabs, beheert die chips produceren, naast het ontwerpen van processors. AMD en Nvidia zijn fabless en ontwerpen alleen de chips die door TSMC worden geproduceerd. Intel hoopt een solide deel van de productiebusiness te krijgen, terwijl het probeert zijn fabs te positioneren voor het maken van AI-chips voor rivaliserende halfgeleiderbedrijven, evenals voor zijn eigen chips.
In het eerste kwartaal rapporteerde Intel een omzetdaling van 10% voor zijn foundry business en operationele verliezen van $2,5 miljard. Maar Intel verwacht kwartaal-op-kwartaal verbetering in zijn foundry business tot 2030.
Intel ziet dat het foundry-segment 40% niet-GAAP brutomarges en 30% operationele marges bereikt tegen het einde van 2030, terwijl het van plan is om het Intel Products-bedrijf te sturen naar een brutomarge van 60% en een operationele marge van 40%.
Na jarenlang achter te hebben gelopen op TSMC, verwacht Intel eindelijk terug te keren naar technologisch leiderschap tegen 2025 met Intel 18A, en zijn vijf-nodes-in-vier-jaar (5N4Y) proces roadmap ligt op schema. De 18A is Intel's next-generation technologie om 1,8 nm chips te produceren. Dit zal gelijk zijn aan TSMC's voorgestelde 2nm rond dezelfde tijd.
Is TSMC's 3nm beter dan Intel's 1.8nm?
TSMC weerlegt echter de claim van Intel door te zeggen dat zijn N3P-proces de technische superioriteit zal behouden over Intel's sub-2nm 18A. N3P ligt op schema om productie gereed te zijn in de tweede helft van dit jaar en zal eerder op de markt zijn. TSMC merkte op dat het N3P-proces de 18A-node van Intel zal evenaren in kracht, prestaties en dichtheid, ondanks het verschil in grootte (van 3nm versus 1,8nm). TSMC zegt ook dat het zal genieten van het vroege mover-voordeel dat het een technische superioriteit zal bieden over de 18A omdat de N3P-nodes tegen lagere kosten zullen komen met bewezen bekwaamheid. NM staat voor nanometer.
TSMC's argumenten over vroege marktvoordelen resoneren enigszins met de opmerkingen van Nvidia-oprichter en CEO Jensen Huang over de strategische noodzaak om voorop te blijven in de AI-race in plaats van slechts te streven naar kleine verbeteringen, toen hij de vraag stelde: "wil je het bedrijf zijn dat baanbrekende technologie levert of het bedrijf dat 0,3% beter levert?" Intel is meestal een achterblijver geweest en is nu bezig met een inhaalrace, in plaats van te genieten van een vroege mover-voordeel.
Intel's Lunar Lake is geweldig maar een beetje te laat voor het Copilot+ PC-feest in juni
Hetzelfde Microsoft dat enthousiast Intel's 18A omarmde, zei dat de nieuwe "Copilot+ PC" AI-functies voor zijn Windows 11 minimaal 40 TOPS (trillion operations per second) vereisen, wat impliceerde dat het niet kon draaien op Intel's Meteor Lake-hardware die 11,5 TOPS levert. Microsoft koos Qualcomm's Snapdragon X Elite die een neurale verwerkingseenheid (NPU) met 45 TOPS biedt.
De Windows Copilot+ PC's helpen gebruikers productiever en creatiever te zijn. Ter referentie: je kunt snel informatie ophalen door aanwijzingen in te typen, snel informatie vinden, creëren, samenvatten en analyseren zonder meerdere apps en bestanden te openen en je woorden omzetten in een PowerPoint-presentatie met visuele elementen.
Met de volgende generatie Lunar Lake gaat Intel voorbij de beperkingen van Meteor Lake. De chipgigant belooft 50% snellere grafische prestaties op Lunar Lake in vergelijking met Meteor Lake. De Lunar Lake zal een NPU hebben die 48 TOPS levert. Dit impliceert dat het de Snapdragon X Elite van Qualcomm zou kunnen overtreffen.
Echter, Qualcomm's Snapdragon X Elite-aangedreven Copilot+ PC's zullen op 18 juni arriveren, wat Qualcomm een voorsprong geeft op Lunar Lake, dat naar verwachting in het derde kwartaal wordt gelanceerd. Ondertussen stelt AMD's Ryzen AI 300 mobiele SoC een nieuwe norm met 50 TOPS (boven de vereiste Copilot+ van Microsoft), en notebooks gebaseerd op deze zullen in juli debuteren. AMD zegt dat het samenwerkt met Microsoft om te voldoen aan de nieuwe Copilot+ normen.
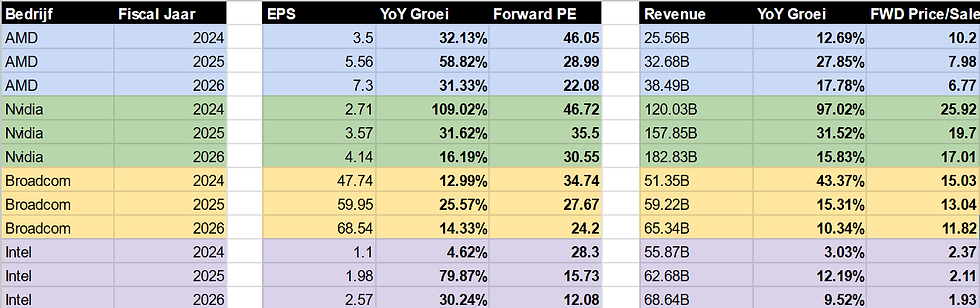
Hoe zit het met de waardering en welke aandelen zijn interessant?
Wil je meer lezen?
Abonneer je op debelegger.nl om deze exclusieve post te kunnen blijven lezen.






































































































































